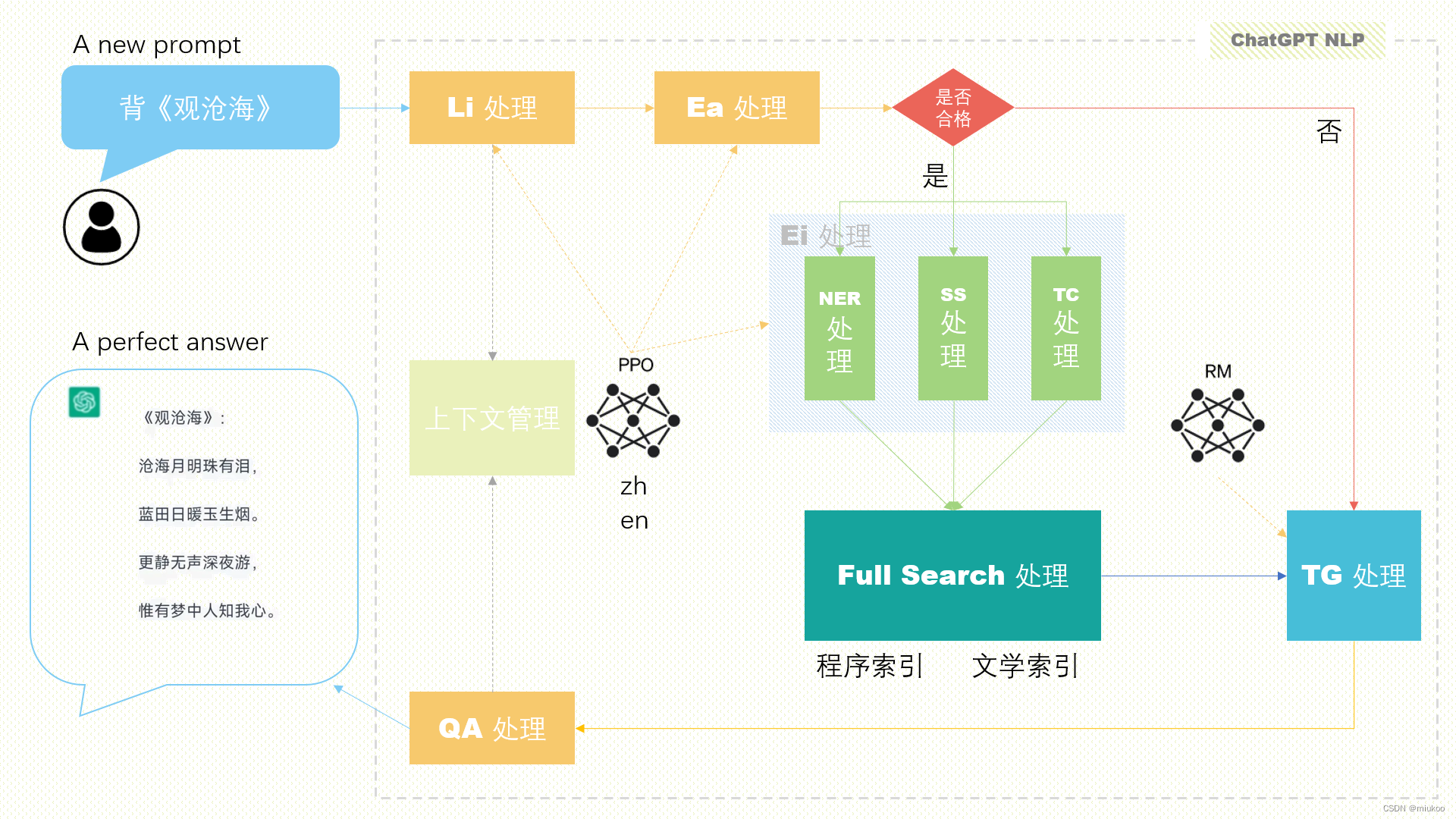
ChatGPT是一个聊天系统,用户输入一句话,那么ChatGPT就需要依据用户输入的信息反馈相关内容,比如上述用户输入“背《观沧海》",系统接收到信息后,就经过以下处理,来为用户生产相对准确的答案:
Li处理:既语言识别(Language identification),ChatGPT是面向中国区之外的用户,因此用户输入的信息有多种语言,至于是那种语言需要先进行识别。识别之后既可以确定在PPO中使用的是中文、还是英文、还是其它模型数据。
Ea处理:既情感分析(Emotional analysis),ChatGPT对于输入信息进行了多中情感分析,如果情感不符合正能量方面的要求,ChatGPT会自动拒绝回答相关用户问题。这点也是非常必要的。Ea处理也需要基于PPO模型库来分析计算。
Ei处理:既抽取信息 (Extract information),从用户输入的信息中提取关键特征,为下一步准备数据
NER处理:既命名实体识别(Named entity recognition),负责提取其中的人名、地名、专业术语等信息
SS处理:既句子相似性处理(Sentence Similarity),用户输入的信息可能存在错别字等信息,通过此步可以进行一个修正
TC处理:既文本分类(Text Classification),把用户输入得信息进行分类,通过此步分类,好定位到下一步搜索用到的相关搜索索引
Full Search 处理:既全文搜索处理,ChatGPT是一个自然语言+搜索引擎集成的架构,通过Ei处理得到的数据就是全文搜索的输入数据,比如EI提取出 NER=观沧海,SS=,TC=文学,那么此步就可以去搜索文学索引中的《观沧海》,得到想要的答案。
TG处理:既文本生成(Text Generation),上一步搜索的结果可能有多条数据,那么那一条最符合用户需求呢?则通过RM模型来进行选取,选取后生成对应的文本内容。
QA处理:既问题解答(Question Answering),把上一步生成的答案进一步转换成适合问答的形式或格式。